chrome.storageの使い方
Chrome拡張の開発中にローカルストレージの使い方で詰まったのでメモ。
公式でドキュメントでわかりにくかった操作をまとめた。
任意のキーで値を保存する
任意のキーで保存するためには {[key]: value} のようにする必要がある。
const key = "YOUR_KEY" chrome.storage.local.set({ [key]: value }).then(() => { console.log("Value is set to " + value); });
全てのキーを取得する
null を指定するとストレージの全ての要素を取得できる。
const keys = await chrome.storage.local.get(null).then((result) => { return Object.keys(result); });
参考
【React Native】WebViewでのログの出し方
React NativeのWebViewでのログの出力方法のメモ。
injectedJavaScript と onMessage を使う。
ボタンをクリックした時にログを表示するサンプル。
console.log() も window.ReactNativeWebView.postMessage() も表示できる。
index.tsx
const debugging = ` const consoleLog = (type, log) => window.ReactNativeWebView.postMessage(JSON.stringify({'type': 'Console', 'data': {'type': type, 'log': log}})); console = { log: (log) => consoleLog('log', log), debug: (log) => consoleLog('debug', log), info: (log) => consoleLog('info', log), warn: (log) => consoleLog('warn', log), error: (log) => consoleLog('error', log), }; `; const onMessage = payload => { let dataPayload; try { dataPayload = JSON.parse(JSON.stringify(payload.nativeEvent.data)); } catch (e) {} if (dataPayload) { if (dataPayload.type === 'Console') { console.info(`[Console] ${JSON.stringify(dataPayload.data)}`); } else { console.log(dataPayload); } } }; return ( <View> <WebView source={{uri: 'file:///android_asset/index.html'}} injectedJavaScript={debugging} onMessage={onMessage} /> </View> );
index.html
<html> <head> <title>Sample</title> </head> <body> <h1>This is WebView sample</h1> <button id="button1">Button1</button> <button id="button2">Button2</button> <script type="text/javascript" src="init.js"></script> </body> </html>
init.js
function send_log() { console.log('This is log'); } const button1 = document.getElementById('button1'); button1.addEventListener('click', send_log, false); function send_log2() { window.ReactNativeWebView.postMessage('Hello'); } const button2 = document.getElementById('button2'); button2.addEventListener('click', send_log2, false);
参考
https://stackoverflow.com/questions/53560744/javascript-console-log-in-a-react-native-webview
【Spring Data JPA】テーブル結合を含むクエリの結果を受け取る
INNER JOIN などのテーブル結合を含むクエリの結果の受け取り方で詰まったのでメモ。
@SqlRusltSetMappingを使用するか、Objectの配列を目的の型に変換する方法がある。
例として、ItemsテーブルとPricesテーブルを結合し、ItemごとのPriceの結果を受け取る。
テーブルの定義
CREATE TABLE items( id BIGINT NOT NULL PRIMARY KEY AUTO_INCREMENT, name VARCHAR(16) NOT NULL ); CREATE TABLE prices( id BIGINT NOT NULL PRIMARY KEY AUTO_INCREMENT, item_id BIGINT, price BIGINT NOT NULL );
方法1 - SqlResultMappingを使う
@SqlRusltSetMappingを使用することで受け取れる。
ただしこの方法は、テーブルに対応しないEntityを作成するので、混乱を招く可能性がある。
結果を受け取るためのクラス(Entity)
@Entity @SqlResultSetMapping( name="ItemPricesResult", classes = { @ConstructorResult( targetClass = ItemPrices.class, columns = { @ColumnResult(name="id", type=Long.class), @ColumnResult(name="name", type=String.class), @ColumnResult(name="price", type=Long.class) } ) } ) @NamedNativeQuery( name="ItemPricesResult", query = "SELECT items.id, items.name, prices.price " + "FROM items " + "INNER JOIN prices ON (items.id = prices.item_id)", resultSetMapping = "ItemPricesResult" ) public class ItemPrices { public ItemPrices(Long id, String name, Long price){ this.id = id; this.name = name; this.price = price; } @Id private Long id; private String name; private Long price; public Long getId() { return id; } public void setId(Long id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } public Long getPrice() { return price; } public void setPrice(Long price) { this.price = price; } }
@Idは必須。 コンストラクタを定義する必要がある。
Service
@Service public class ItemService { @PersistenceContext EntityManager entityManager; public List<ItemPrices> getItemPrices(){ return entityManager.createNamedQuery("ItemPricesResult").getResultList(); } }
repositoryを介さずに呼び出せる。
方法2 - Objectの配列として受け取り変換
新しいDtoを作成する。
@Data @AllArgsConstructor public class ItemPriceDto{ private Integer itemId; private String name; private Integer price; public ItemPriceDto(Object[] objects) { this( ((BigInteger) objects[0]).intValue(), (String) objects[1], ((BigInteger) objects[2]).intValue() ); } }
Repository
public interface ItemRepository extends JpaRepository<Item, Integer> { @Query( value ="SELECT items.id as item_id, items.name, prices.price " + "FROM items " + "INNER JOIN prices ON (items.id = prices.item_id)", nativeQuery = true ) List<Object[]> findItemPricesRaw(); default List<ItemPriceDto> findItemPrices(){ return findItemPricesRaw() .stream() .map(ItemPriceDto::new) .collect(Collectors.toList()); } }
findItemPriceRawはObjectの配列を返す。
これをItemPriceDtoのリストに変換する。
戻り値が1つのときは、objectの0番目の値を指定してコンストラクタに渡す。
public interface ItemRepository extends JpaRepository<Item, Integer> { @Query( value ="SELECT items.id as item_id, items.name, prices.price " + "FROM items " + "INNER JOIN prices ON (items.id = prices.item_id) " + "WHERE items.id = :itemId", nativeQuery = true ) Object[] findSingleItemPriceRaw(Integer itemId); default ItemPriceDto findSingleItemPrice(Integer itemId){ Object[] objects = findSingleItemPriceRaw(itemId); ItemPriceDto itemPriceDto = new ItemPriceDto((Object[]) objects[0]); // objectsの0番目の値を指定 return itemPriceDto; } }
参考
2.3.2. ネイティブクエリのマッピング JBoss Enterprise Application Platform 5 | Red Hat Customer Portal
Javaの標準入力
諸事情によりJavaで競プロをすることになったので、標準入力の方法をまとめます。
初心者なのでとりあえずScannerでの受け取り。
1行に1つの文字または数字
最も基本となる標準入力方法。
Scanner sc = new Scanner(System.in); int n = sc.nextInt();
型にあわせて
- nextLong()
- next()
を使う。
1行に複数の数字(配列へ)
11 234 55など。
Scanner sc = new Scanner(System.in); int[] a = new int[n]; Arrays.setAll(a, i -> sc.nextInt());
nextInt()をfor文でまわすだけの方法もある。
Scanner sc = new Scanner(System.in); int[] numbers = new int[n]; for(int i=0; i<n; i++){ numbers[i]=sc.nextInt(); }
1行に複数の文字列(配列へ)
foo bar hogeなど。
Scanner sc = new Scanner(System.in); String[] words = sc.nextLine().split(" ");
1つの文字列を1文字ずつ配列へ
oo..xoxxx.oなどを受け取る。
Scanner sc = new Scanner(System.in); char[] s = sc.next().toCharArray();
複数行の文字列(地図など)
###..##などで表現される地図を受け取る。
Scanner sc = new Scanner(System.in); char[][] map = new char[r][c]; for (int row = 0; row < r; row++) { map[row] = sc.next().toCharArray(); }
【レビュー】HUAWEI Band 4 Pro を買いました
ランニングの距離やペース記録用に買いました。
HUAWEI Band 4 Proの赤です。
他には黒とピンクがあります。

これよりも低価格のスマートバンドとして、XiaomiのMiスマートバンド4、HUAWEIのHUAWEI Band 4があります。
スマホを持たずランニングのペースを記録したかったので、GPS内蔵のHUAWEI Band 4 Proを選びました。
価格は約7000円でした。
GPSのないモデルと比較すると3000円ほど高くなっています。
GPS内蔵ではApple Watchがありますが、いきなり数万出す勇気がなく、こちらを選んだ次第です。
目次
スペック
公式のHPによるとスペックは以下の通りです。

特徴としてはGPSが内蔵されていることですね。
これによってスマホを持たずともランニングの記録ができます。
その他の機能は一般的なスマートバンドと変わらないと思います。
外観
内容物は本体と充電器と説明書、保証書でした。
色はAmazonの写真の通り綺麗な赤で満足です。

10円玉と比較したときのサイズです。
他のスマートバンドと差はないかと。

一つの残念ポイントは充電器ですね。
クレードルにmicro USBを接続する仕様になっています。
この接続がType-Cだったらよかったんだけど...

ペアリング
HUAWEI HEALTHというアプリを使ってペアリングします。
ペアリングに当たってはHUAWEI IDを取得する必要があります。
何かと話題の企業なので抵抗ありましたが、しかたなく登録。
連絡先を同期してって言ってきますが、許可しなくてもOKでした。
ペアリングは一瞬でできましたが、スマートバンドのアップデートに1時間かかりました。
使用感
つけ心地は普通の腕時計と同じです。
バンドの長さが17段階で調節できます。腕の太い人も細い人も使えそうです。
バッテリーのもちは72時間(GPS使用1時間) でした。
GPSを使用時間を踏まえても公式のスペックよりは短いですね。
ただ、明るさの調節や画面を操作する回数を減らせば、もう少し持ちそうです。
以下それぞれの機能の使用感です。
ランニング
記録できるのは、
- ランニング時間
- 1kmあたりのペース
- 平均速度
- 歩数
- 平均歩幅
- 経路
- 心拍数
- 消費カロリー
などの情報です。
ランニング中は1kmごとに通知してくれたり、ペースや心拍数を表示してくれます。
ランニング後には経路やペースの詳細をアプリで確認することができます。
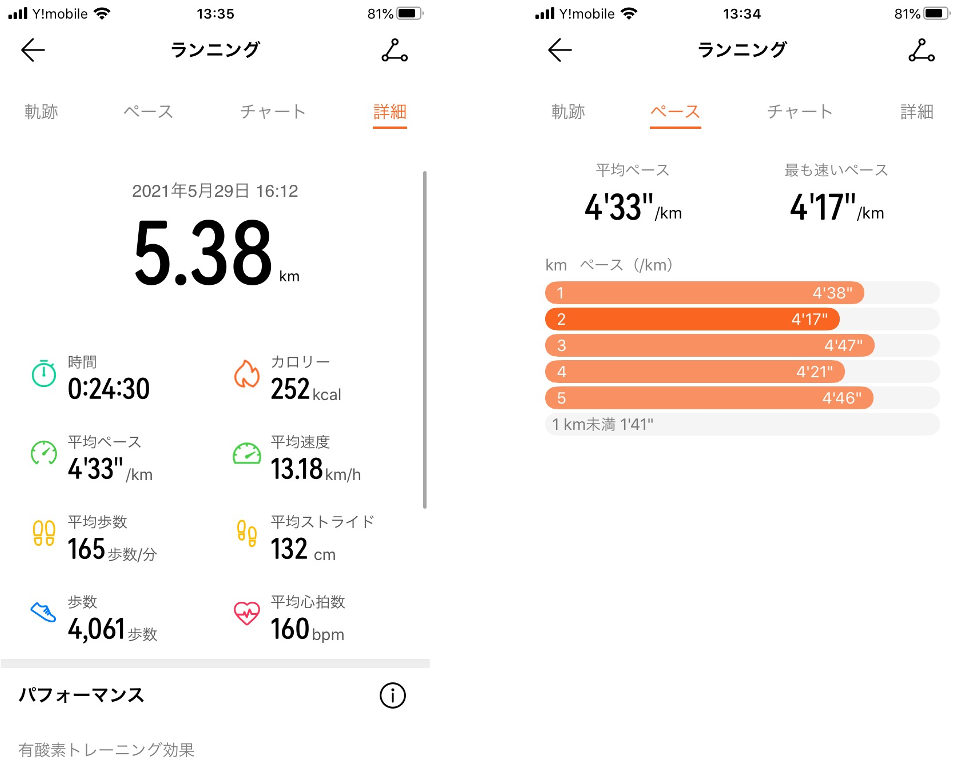
スマートバンド単体でのGPSの精度もかなり良く、走った経路を正確に取れていました。誤差は概ね20m程度です。
さまざまな情報がわかり、モチベーションが上がるので楽しいです。
睡眠
睡眠時間を判断し、自動的に記録してくれます。 眠りの深さから睡眠を3段階に分割し、それぞれ何時間だったかを分析してくれます。
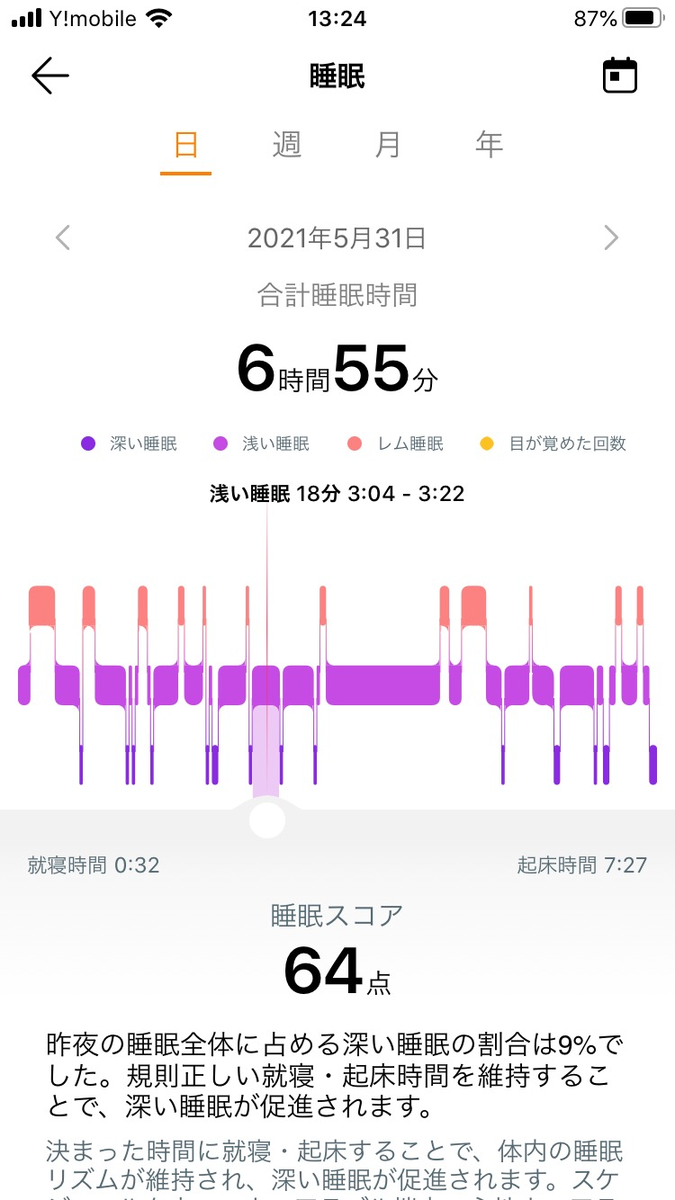
このように深い睡眠、浅い睡眠、レム睡眠がそれぞれ何分だったかがわかります。自分は深い睡眠がほとんどないようです。
ただ、睡眠時間のアプリへの同期に3分ほどかかるのが少し残念です。
できれば起床直後にデータを確認したいです。
まとめ
以上、HUAWEI Band 4 Proのレビューでした!
今回はランニングと睡眠の記録しか使用しませんでしたが、他のスポーツの記録にも対応しています。
スマートバンドデビューにちょうど良い価格と機能です。
気になっている人は買ってみてはいかがでしょうか。
物体検出の評価指標(APとmAP)
AP、mAPの計算方法のまとめです。
Precision, Recallなどの定義は前回の記事を参考にしてください。
目次
APとは
Average Precisionとも呼ばれます。
Precision-Recall曲線の下の部分の面積がAPとなります。
例えば、「自転車」を検出した結果が以下のようになったとします(Confidence Score順に並んでいます)。

これを縦軸にPrecision、横軸にRecallをとってプロットすると、以下のような図になります。
((Precision, Recall) = (1,0), (0,1)を追加)

この図の線の下の部分の面積がAPとなります。
mAPとは
Mean Average Precisionとも呼ばれます。
モデルが検出できる各クラスに対するAPの平均です。
クラス数をC、クラスiのAPをAPiとすると、mAPは次の式で表せます。
全部のクラスに対するAPの平均です。
最後に
以上、簡単ですがAP、mAPのまとめでした。
間違いやご指摘あればコメントにて教えていただきたいです。
Pythonの多次元リストのソートについて
Pythonの多次元リストをソートする時にいつも忘れるのでメモ。
TL;DR
多次元リストを二次元目の値でソートする方法
key=lambda x:x[1] とします。
l = [[111, "さしすせそ"], [222, "あいうえお"], [333, "たちつてと"], [444, "かきくけこ"]] sorted_l = sorted(l, key=lambda x:x[1]) print(sorted_l) # 実行結果 [[222, 'あいうえお'], [444, 'かきくけこ'], [111, 'さしすせそ'], [333, 'たちつてと']]
2次元目の値でソートできました。
なにをやっているのか
sorted()の2つめの引数に関数を設定することができます。
ソートするときに関数を適用した値をソートします。
上の例ではラムダ式を適用した結果をソートしているのです。
絶対値でソートするときは以下のようにします。
l = [2,-3,4,1] sorted_l = sorted(l, key=abs) print(sorted_l) # [1, 2, -3, 4]
絶対値の昇順でソートできました。
なお、返ってくるリストには 関数適用前の値 が入ります。
この例であれば、-3が入っていることがわかります。
ついでに
降順にソートするときは reverse=True とします。
l = [2,-3,4,1] sorted_l = sorted(l, key=abs, reverse=True) print(sorted_l) # [4, -3, 2, 1]